My former and current projects
TomoATT : Eikonal equation based adjoint-state travel-time tomography
I am currently working on this project. Workin as a lead developer of an open-source code project TomoATT, which is a library for eikonal equation based adjoint-state travel time tomography, optimized for a use on HPCs (implemented with MPI, MPI-SHMEM, GPU with SIMD optimization, and parallel-HDF5, containerlized with Docker and Singularity). Built up an opensource project TomoATT : https://github.com/MIGG-NTU/TomoATT
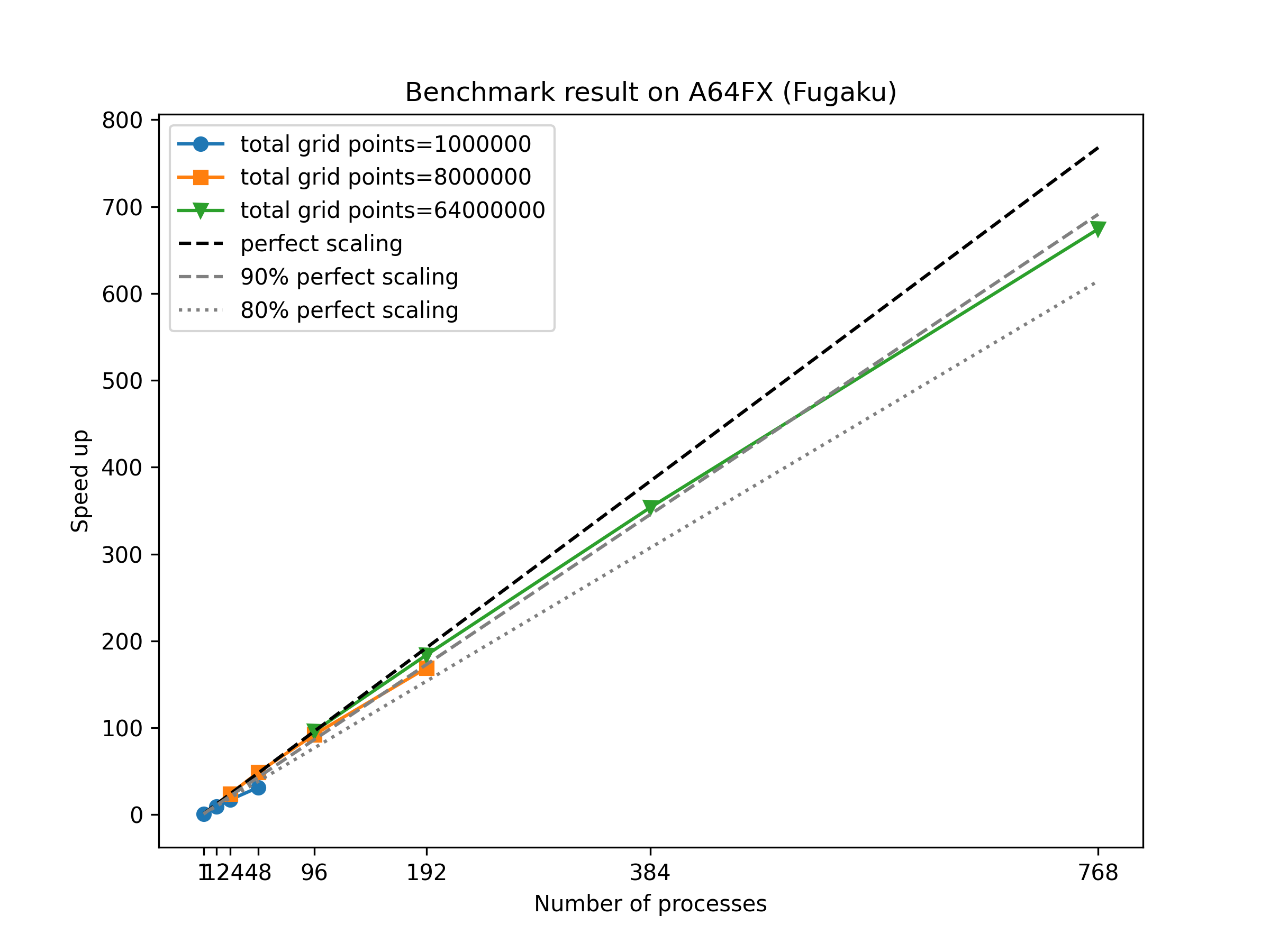
Obtained 2 HPC allocations for TomoATT project:
- FUGAKU Riken, Japan, 2022, hp220155, 315,634 Node hours (x48 CPU hours)
- ASPIRE1&2A NSCC, Singapore, 2022, 12002694, 1,574,400 CPU+GPU hours
- ASPIRE2A,NSCC, Singapore, 2023, 12002694, 2,620,000 CPU+GPU hours
One full article and 6 conferences resulted by TomoATT.
![]()

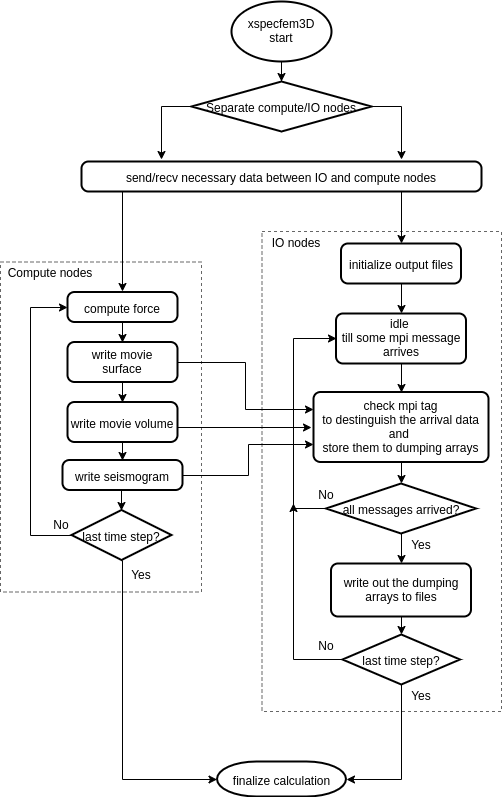
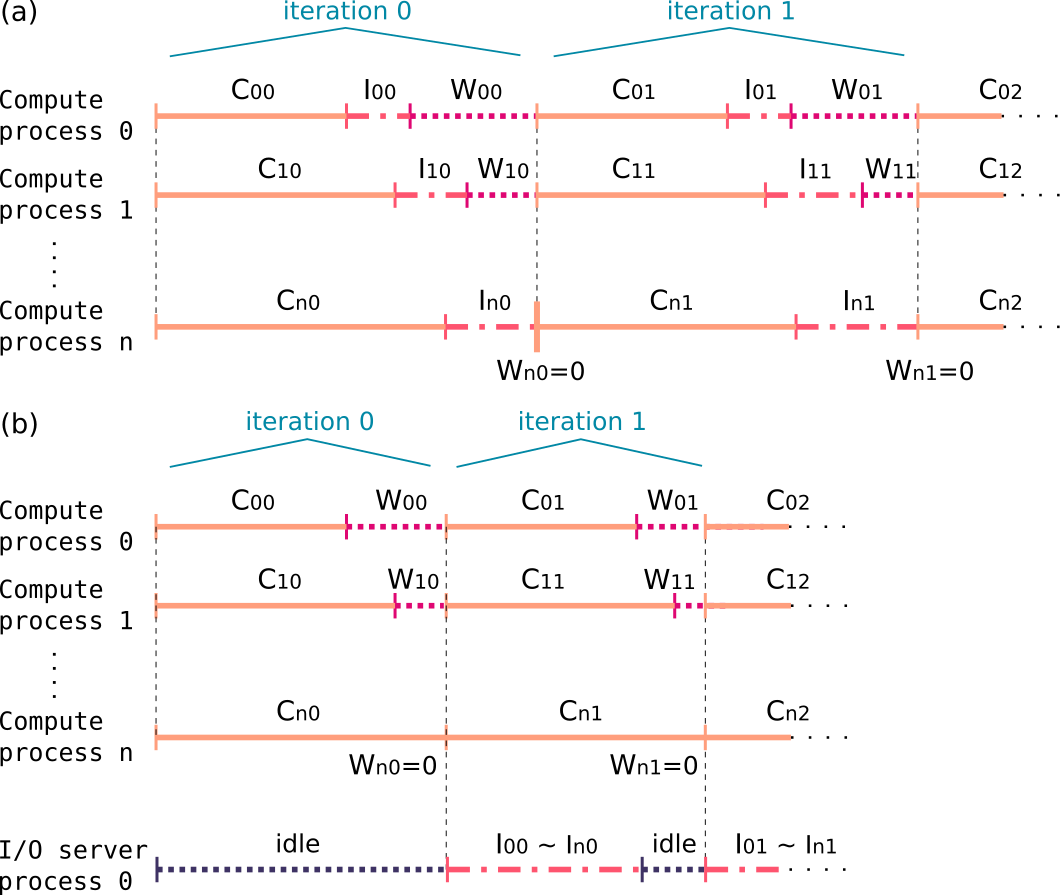
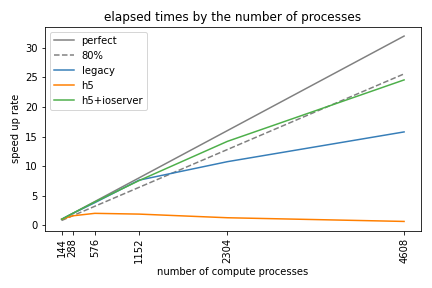
I/O optimization and designing/developing a workflow toward a full-wave inversion calculation on Exascale HPC machines.
This was a project (part of my former postdoc work) for code optimization towards use on Exascale High Performance Computers or supercomputers.
The I/O is one of the significant bottlenecks for achieving a scalable computation,
because the limitation of file I/O bandwidth blocks the other computing processes.
To avoid this waiting time, I implemented an advanced way of using multi-processors, i.e. preparing some I/O dedicated nodes (we call this I/O server) then the computing process may only do their computation while actual I/O processes are done on only the I/O servers, which realize asynchronous I/O.
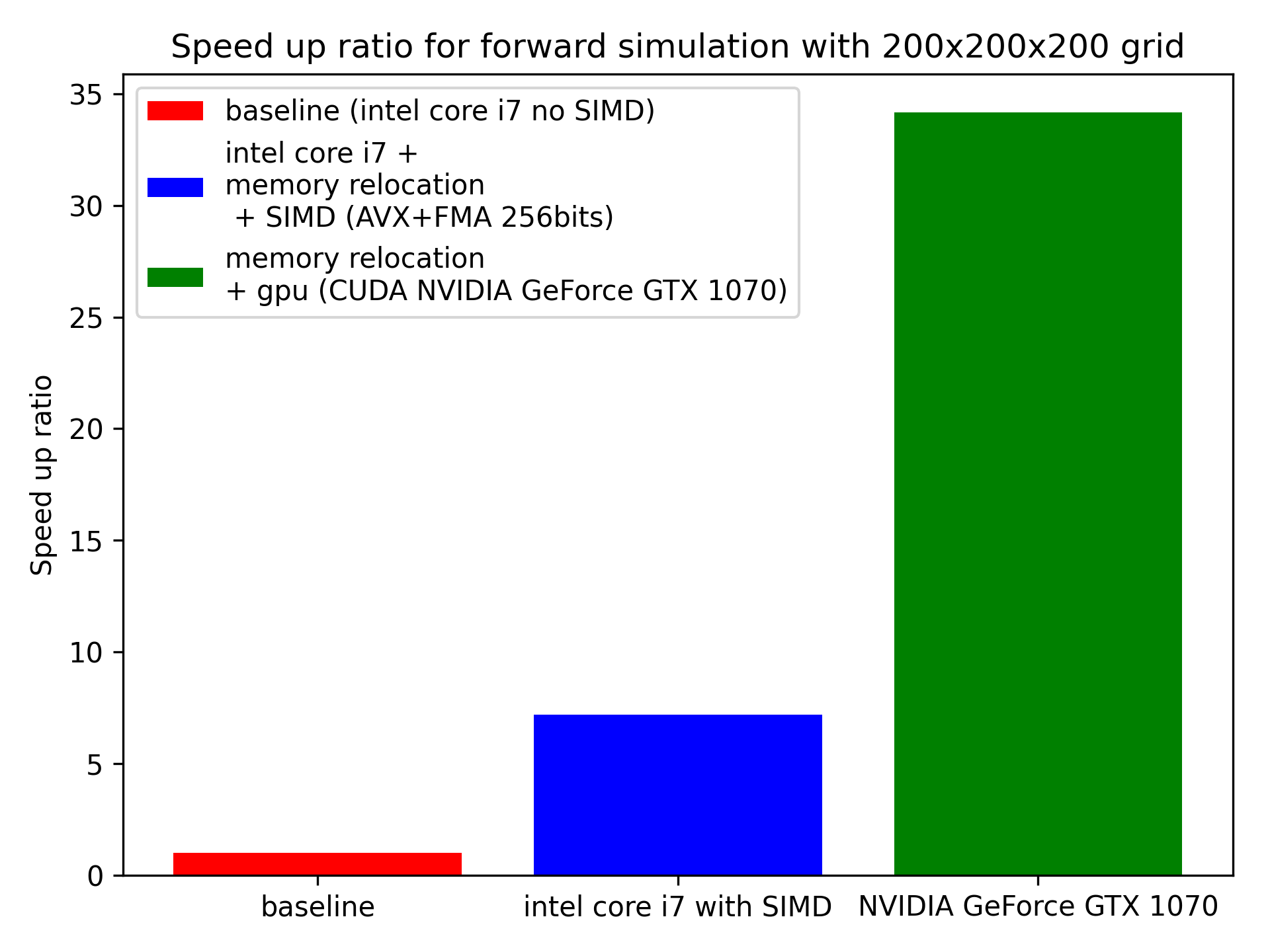
Full wave inversion and development of pre/post processing tool for massive amount of seismic observation data.
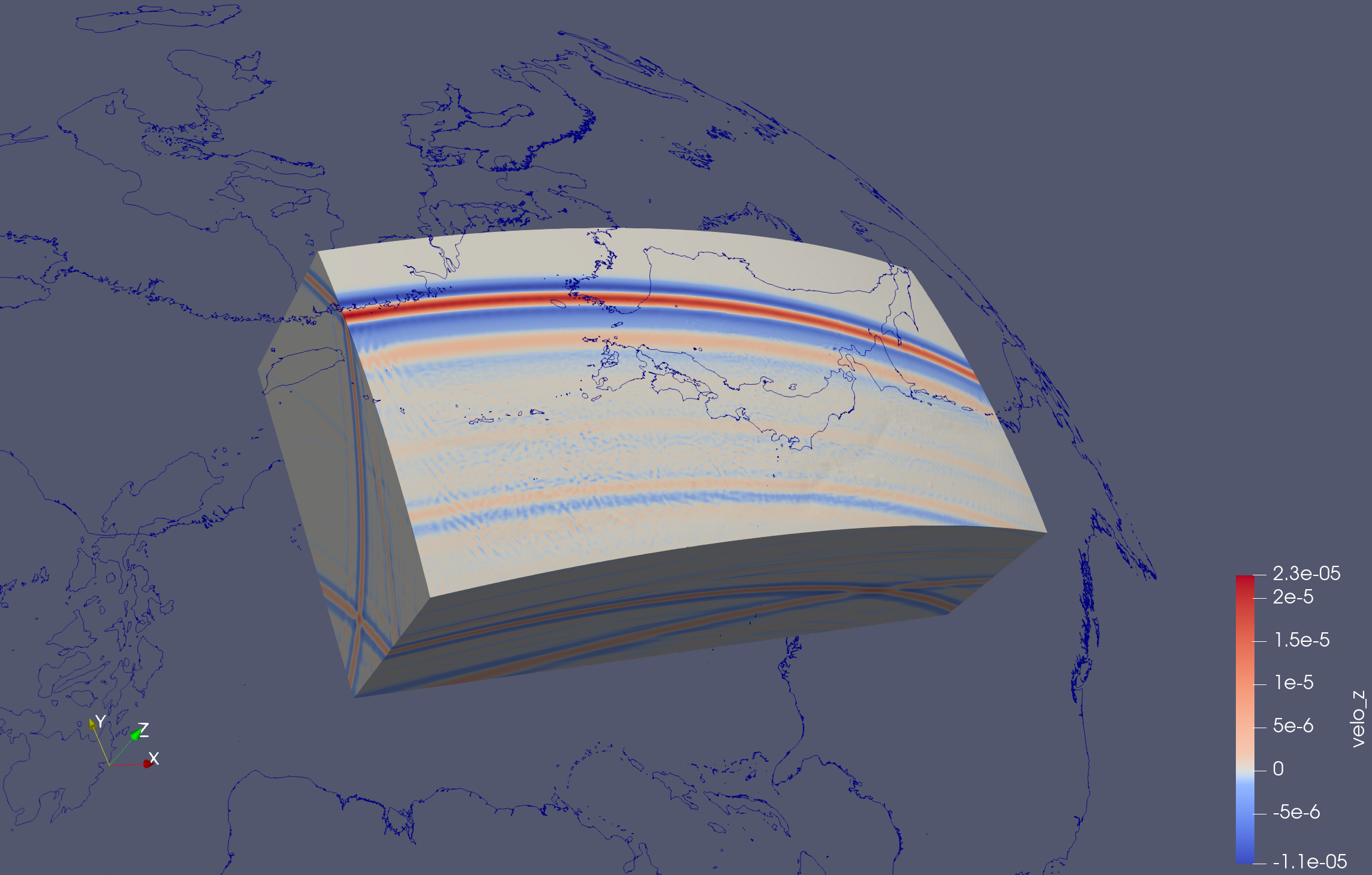
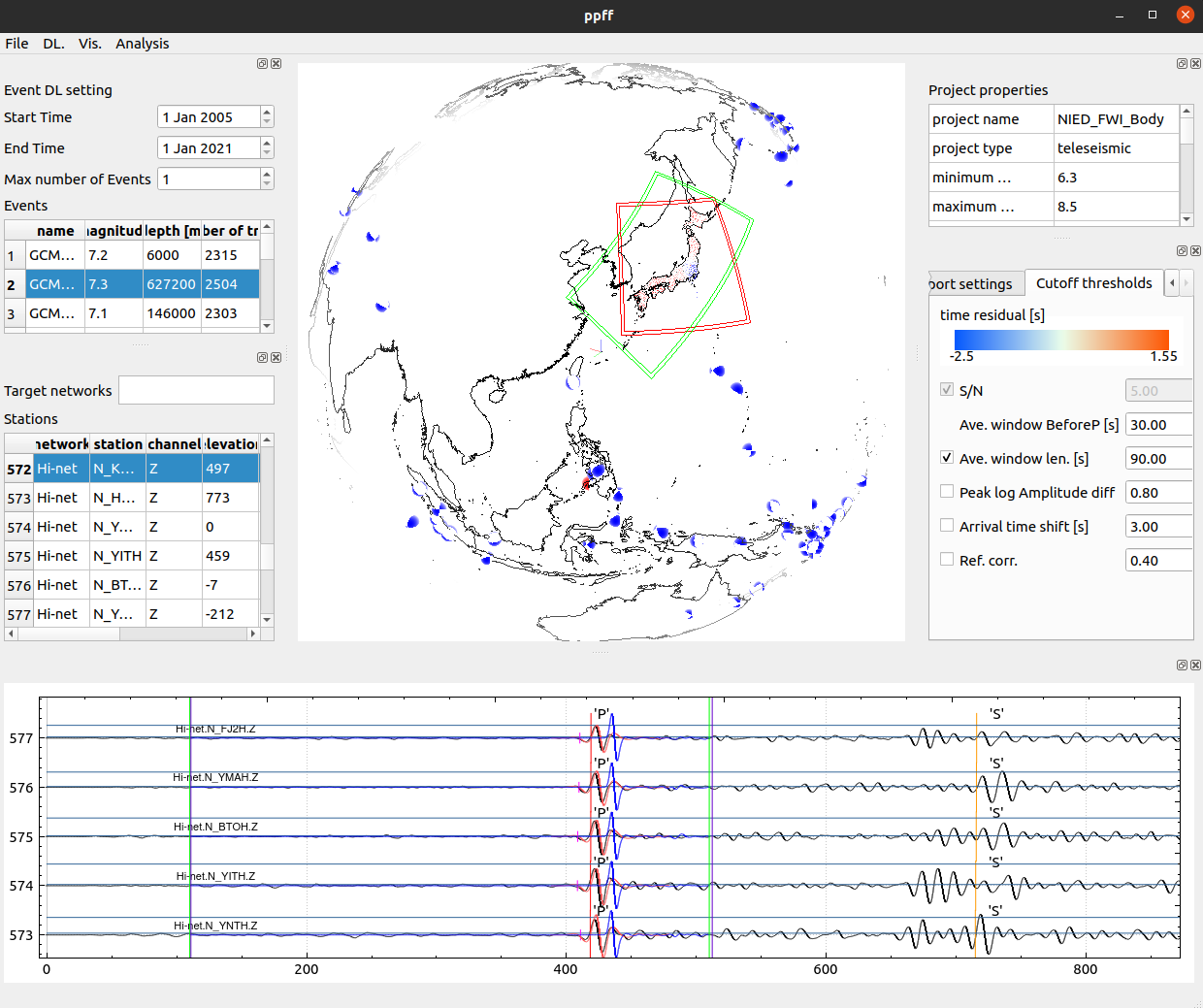
This aws the project (part of my former postdoc works) to realize seismic tomography using Spectral Element Method and Full wave inversion for studying the subsurface structure of Japanese islands.
I was developing an Gui application for downloading, pre/post-processing, configurating a set of files/scripts for running a full wave inversion and shipping the massive seismic observation data to HPC and computation clusters.
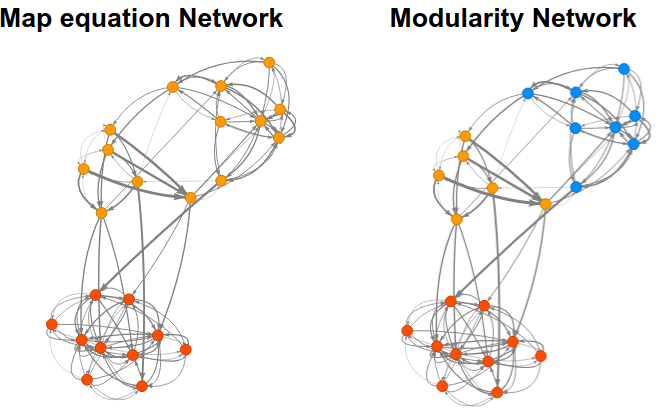
Network clustering application
Implementation of hierarchical network clustering code, based on Map equation (Rosvall 2008, 2010, 2011) and Modularity (Clauset 2004).
The search algorithm may be selected from the Louvain method (Blondel 2008) or the Modified Louvain method (Rosvall 2010).
For the calculation of transition probability, users may select from Standard teleportation, Recorded link teleportation, or Unrecorded link teleportation (Lambiotte 2012).
Convergence calculation is done by the Arnoldi method or Power method.
Keywords: Map equation, Modularity, Louvain method, Page rank
The numerical computation library for estimation of subject times
Python library for calculating the subject time (i.e. temporal position indicating the degree of progress in a disease) written in C++ and wrapped by SWIG.
In the calculation routine of this library, nonlinear mixed effect modeling was implemented for calculating averaged curves of multiple biomarkers (i.e. fixed effects) and random parts which depends on each subject.
The golden search algorithm was also implemented.
This code was developed as a part of a research project by Dr. Keita Tokuda, a project researcher at The University of Tokyo Hospital (now at University of Tsukuba).
Keywords: Maximum likelihood estimation, Nonlinear mixed effect model, Golden search
Improvement of multi-label classification using C2AE and fine-tuning with Transformer-lm
In order to improve the accuracy of a multi-label classification task with Canonical Correlated AutoEncoder (C2AE) using a limited amount of input text, we applied the method of “Improving Language Understanding by Generative Pre-Training”, commonly known as “finetune-transformer-lm”.
Keywords: Natural language processing, Deep Learning, multi-label classification, Transformer, Language model, C2AE
Generation of semantic networks with review texts of popular products and generation of learning model for creating a new hit product
This was a part of another research project on “computational creativity” by Dr. Akihito Sudo, a researcher/research manager at The University of Shizuoka.
First, we generate two semantic networks, one is generated from reviews texts written for a hit product and another is from reviews for multiple products in the category to which the target product belongs.
Using these semantic networks and the differences between them as a dataset, we were trying to generate a learning model that can generate keywords for the next hit products.
Keywords: Natural language processing, word2vec, Semantic network, Machine learning, SMOTE
Web scraping scripts
This is a set of scraping scripts developed for gathering review texts from Amazon.com/co.jp to generate semantic networks concerning the above project.
A python library “Scrapy” was used as the engine for the scraping spiders.
Keywords: Web Scraping